Why Tapdata
Products



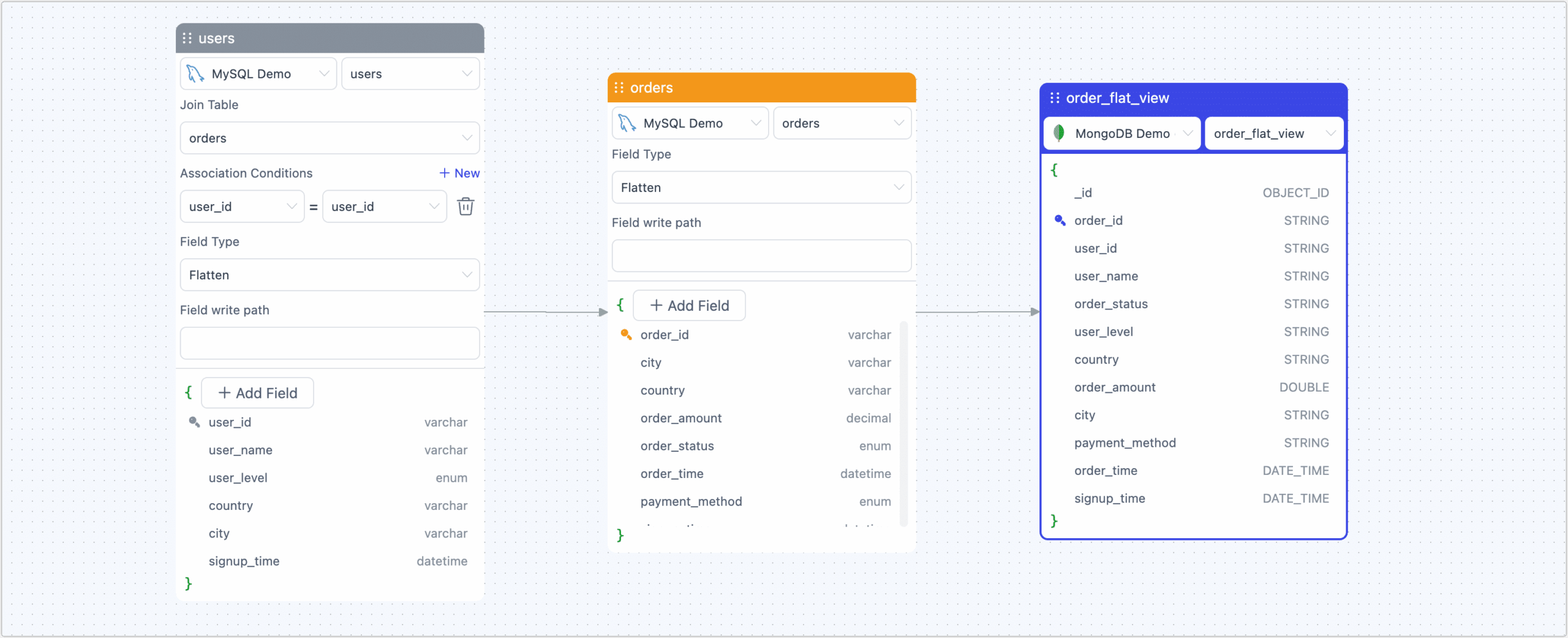
Tapdata Live Data Platform
The Tapdata Live Data Platform visualizes the construction of an enterprise real-time data service platform in a very short period of time, enabling low-cost implementation of Data as a Service.






Customers




Pricing
Tapdata has served leading customers in dozens of industries such as retail, manufacturing, government affairs, finance, medical care, logistics, education, energy, and the Internet, and has been widely acclaimed
Community
GitHub














Resource
 Blogs
Blogs
 Technical Analysis
Technical Analysis
 Application Scenario
Application Scenario
 Best Practices
Best Practices
 News information
News information
 Quick Start Video
Quick Start Video
 Live playback
Live playback
 Product Demo
Product Demo
Documentation
 Quick Get Start
Quick Get Start
 Preparation
Preparation
 User Guide
User Guide
 Common Problem
Common Problem
White Papers